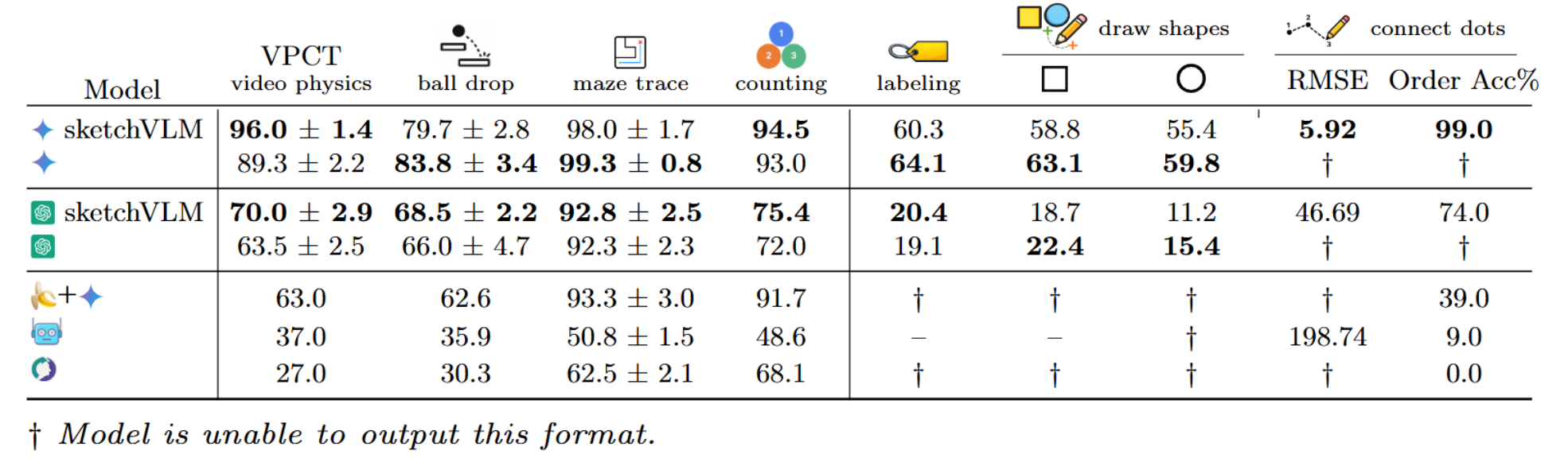
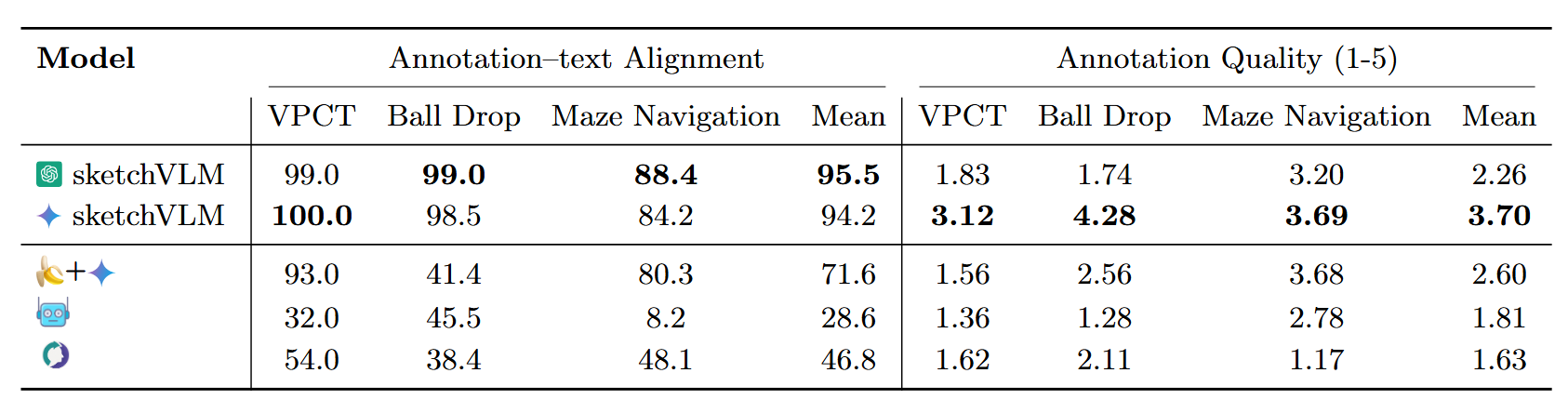
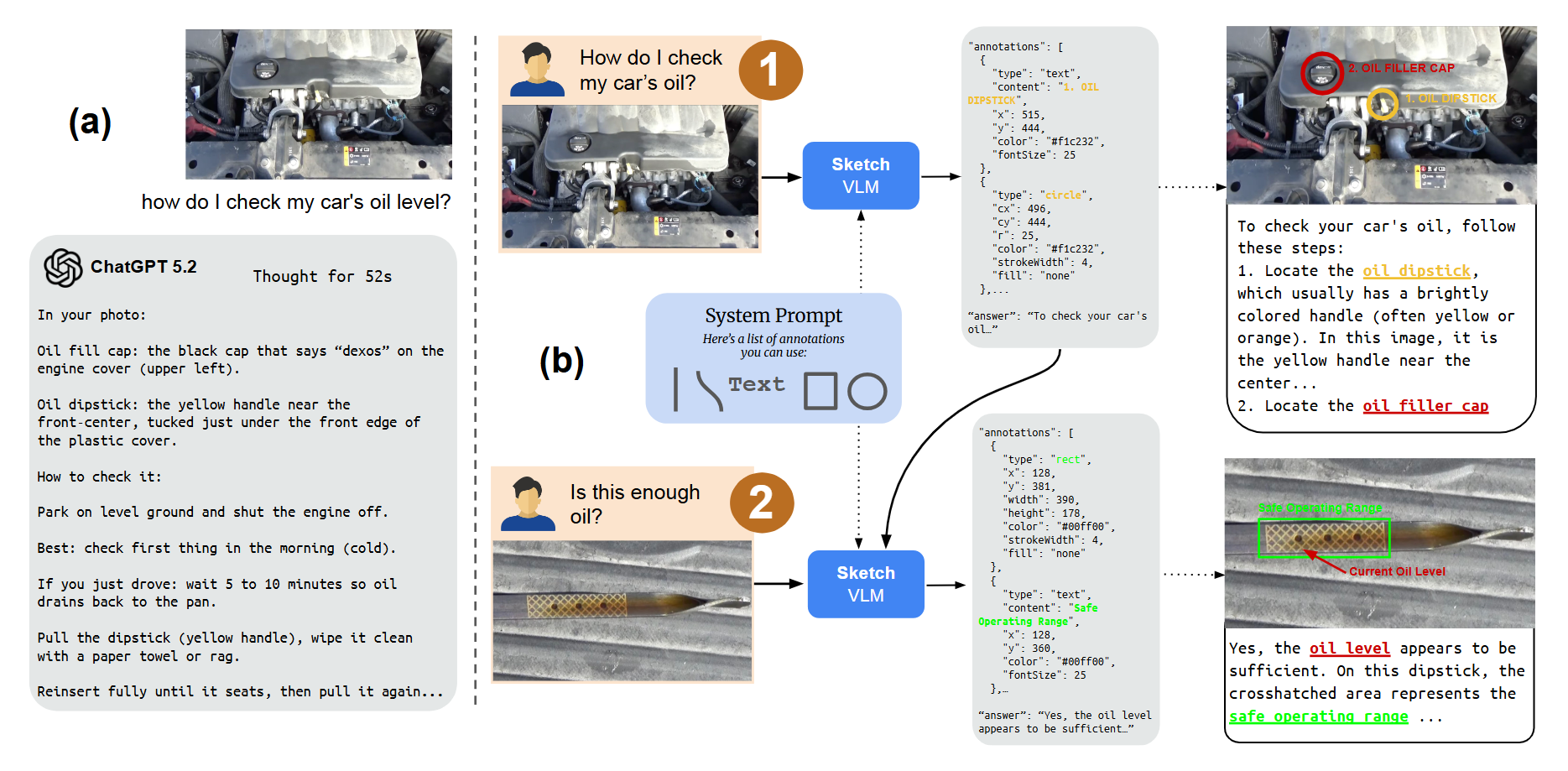
When answering questions about images, humans naturally point, label, and draw to explain their reasoning. In contrast, modern vision–language models (VLMs) such as Gemini-3-Pro and GPT-5 typically respond with only text, which can be difficult for users to verify. We present SketchVLM, a training-free, model-agnostic framework that enables VLMs to produce non-destructive, editable SVG overlays on the input image to visually explain their answers. Across six benchmarks spanning visual reasoning (maze navigation, ball-drop trajectory prediction, and object counting) and drawing (part labeling, connecting-the-dots, and drawing shapes around objects), SketchVLM improves visual reasoning task accuracy by up to +28.5 points and sketch quality by up to +48.3% over image-editing and fine-tuned sketching baselines, while also producing sketches that are more faithful to the model's stated answer. We find that single-turn generation already achieves strong accuracy and sketching quality, and multi-turn generation opens up further opportunities for human-AI collaboration.
 Training-free
Training-free (locate and connect numbered dots in order), Drawing Shapes around Objects
(locate and connect numbered dots in order), Drawing Shapes around Objects  (localize COCO objects with rectangles or ovals), and Part Labeling
(localize COCO objects with rectangles or ovals), and Part Labeling  (place text labels at correct part locations on PACO/Pascal-Part images). Visual reasoning tasks test whether sketching helps models think: Maze Navigation
(place text labels at correct part locations on PACO/Pascal-Part images). Visual reasoning tasks test whether sketching helps models think: Maze Navigation 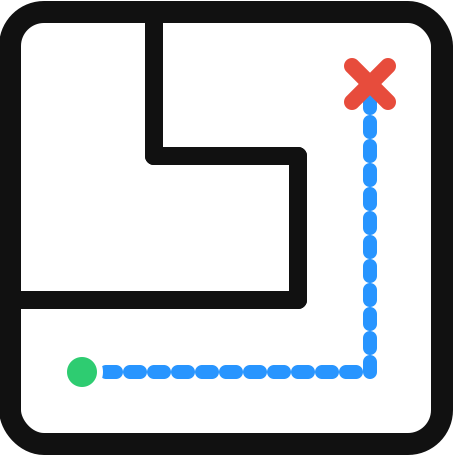 (trace a path through a 3×3 grid maze), Physics Ball Drop
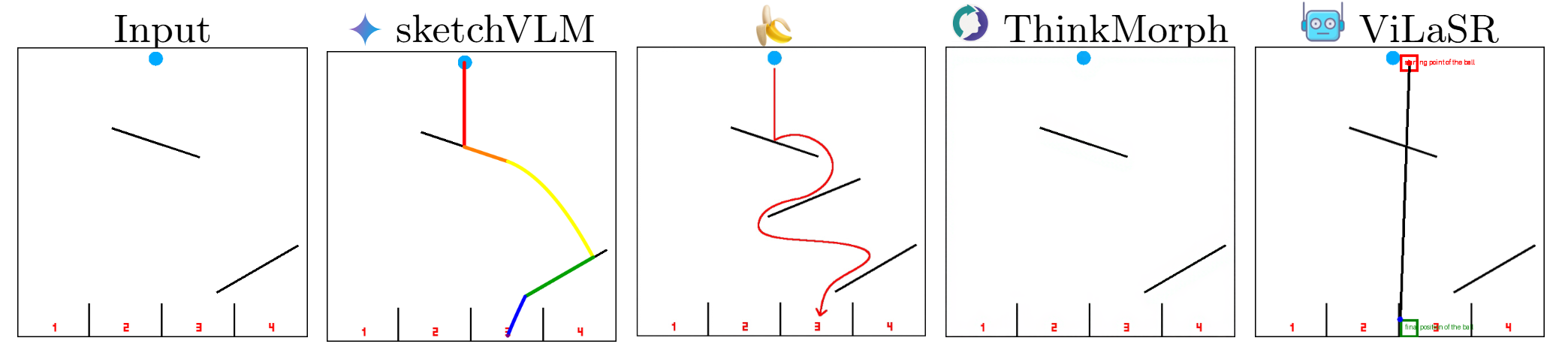
(trace a path through a 3×3 grid maze), Physics Ball Drop 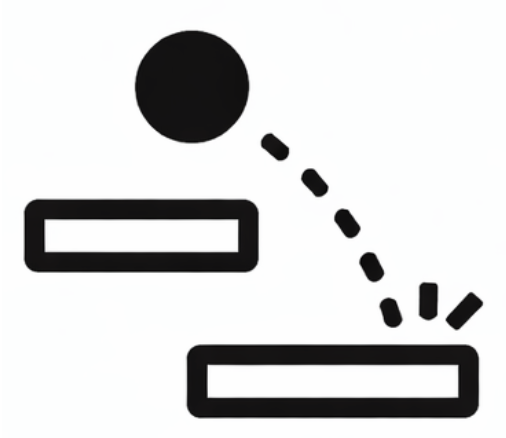 (predict which container a dropped ball lands in), and Object Counting
(predict which container a dropped ball lands in), and Object Counting  (count and mark every instance of an object).
(count and mark every instance of an object).
 and GPT-5
and GPT-5  ) against the state-of-the-art image-editing model Nano Banana Pro
) against the state-of-the-art image-editing model Nano Banana Pro  , which generates annotations by editing the image directly and by comparing against the fine-tuned sketching models ViLaSR
, which generates annotations by editing the image directly and by comparing against the fine-tuned sketching models ViLaSR  and ThinkMorph
and ThinkMorph  , which are trained specifically to produce visual reasoning traces.
, which are trained specifically to produce visual reasoning traces.